【生成AI×設備保全 #5】設備保全データ構造の実装 — スキーマ設計とセマンティック技術
保全データの構造化(スキーマ)と意味付け(セマンティック)の具体的な実装手順を解説。正規化の5ステップからSKOS辞書化、RDF/OWL知識グラフ構築まで、古典的正規化と知識グラフ化処理の正攻法を保全データの実例とともに詳述する。

1. データの構造化(スキーマ)── 古典的正規化の現代的意義

1-1. 構造化の本質は正規化にある
データの構造化と聞くと最新の技術を想像するかもしれないが、その本質は1970年にE. F. Coddが提唱した関係モデル[1]に基づく正規化という、データベース理論における古典的な手法である。正規化とは、データを「マスタ」(設備名称・部品仕様など変わりにくい基礎情報)と「トランザクション」(点検記録・故障報告など都度発生する事実データ)に分離し、各テーブル間の依存関係を明確にする操作を指す。
この古典的手法がLLM時代に改めて重要性を増している理由は、Text2SQL技術の動作原理にある。Fürst et al.がEDBT 2025で報告した研究[2]は、データモデルの設計がText2SQLシステムの正答率に顕著な影響を与えることを実証している。スキーマの設計が適切でない場合、LLMが生成するSQLクエリは複雑な集合演算(UNION等)を含む冗長な構造となり、実行精度が低下する。逆に、正規化が適切に施されたスキーマではSQLクエリが簡潔になり、LLMによるSQL生成の安定性が向上する。
1-2. ステップ1:入力データの棚卸し
構造化の第一歩は「何を集めるか」の定義である。点検票(PDF/Excel/紙)、設備台帳、部品リスト、作業指示、故障記録、部品入出庫記録など、バラバラな形式でも構わないので、範囲と期間を決めてデータソースの棚卸しを行う。
この段階で重要なのは、完璧なデータを求めないことである。現場に存在するデータは、形式も粒度もまちまちであることが通常であり、それ自体は問題ではない。問題は、それらを「そのまま」AIに投入することにある。
1-3. ステップ2:デジタル化と抽出
収集されたデータから共通の列を定義し、表形式で定型化する。OCRによる紙データの認識やExcelのQuery機能等を活用してデジタル化を進める。ここでの目的は、データを一つの統一的な表形式に落とし込むことであり、内容の精査は次のステップに譲る。
1-4. ステップ3:クリーニング(一セル一事実)
データ構造化においてもっとも地道かつ重要な工程がクリーニングである。表記ゆれの統一(日付形式、単位表記等)、項目分解(「45℃/異常」→ 値=45.0/単位=℃/異常フラグ=true)といった処理により、「一つのセルに一つの事実」という原則を徹底する。
この原則は単純に見えるが、保全データにおいては実務的な困難が伴う。たとえば「ポンプ異音あり、ベアリング交換実施」という一文が自由記述欄に入力されている場合、これは「症状=異音」「対象部品=ベアリング」「作業内容=交換」という3つの事実を含んでいる。これらを分離して各列に格納することが、LLMによる正確な検索と推論の前提条件となる。
1-5. ステップ4:マスタ整備
設備・部品・点検項目の「揺るぎない定義」を作成する。設備マスタでは内部用ID(例:asset_id)と現場コード(例:P-001)を定義し、部品マスタでは設備との紐づけと部品自体の仕様情報を整備する。Kimball & Rossの『The Data Warehouse Toolkit』[3]が体系化した次元モデリングの手法は、この設計段階で有用な参照枠となる。
テーブル | キー項目 | 格納内容 |
|---|---|---|
--- | --- | --- |
設備マスタ | asset_id, 設備ID | 設備名称、所在地、設備区分 |
部品マスタ | material_id | 品目名、仕様、対応設備 |
保全履歴(トランザクション) | report_id, asset_id | 工事内容、日時、担当 |
点検履歴(トランザクション) | ins_id, asset_id, 点検項目 | 数値、単位、異常フラグ |
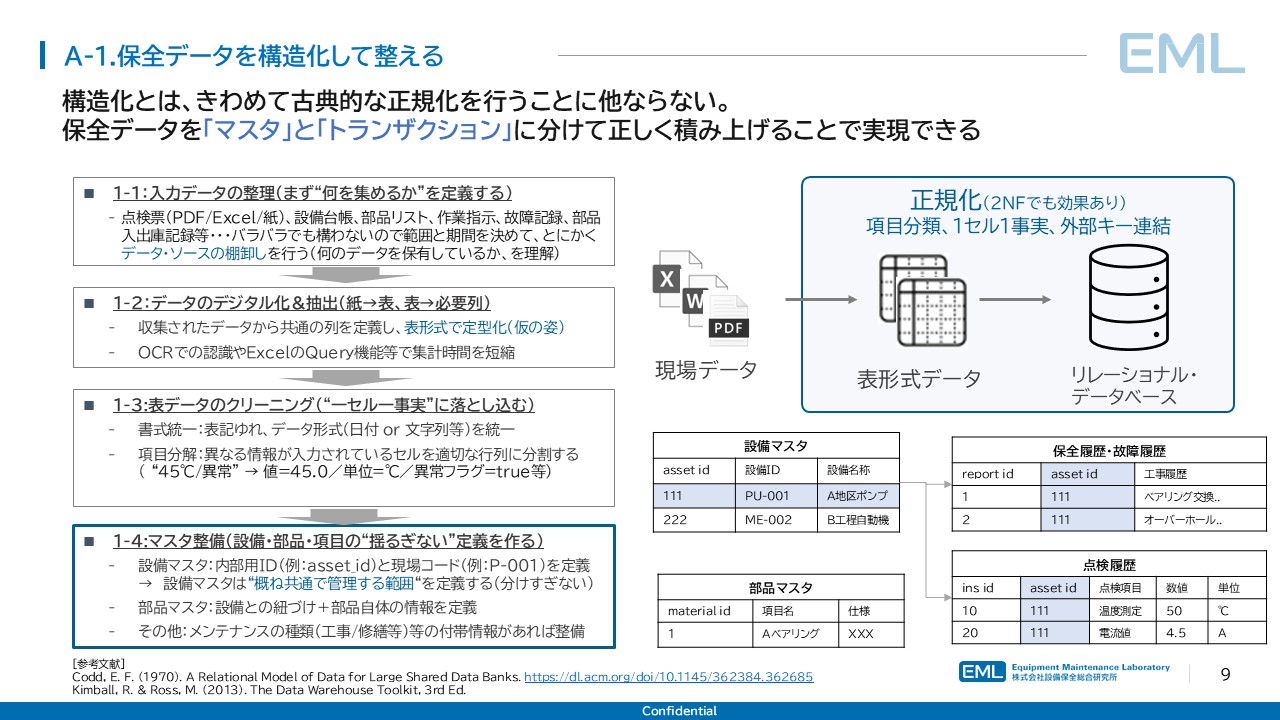
1-6. ステップ5:トランザクション設計とリレーション構築
都度発生する保全活動を「見出し(ヘッダ)」と「明細(ライン)」で整理する。たとえば点検トランザクションでは、見出しに「点検番号|設備ID|点検日時|担当」、明細に「点検番号+項目ID|値|単位|異常フラグ」を格納する。保全作業トランザクションでは、見出しに「作業指示番号|設備ID|計画/実績日時|作業種別|結果」、明細に「使用部品|手順|所要時間」を配置する。
最後に、設備マスタ─保全作業トランザクション等の繋がりがあるデータをIDで関係づけ、ER図(Entity-Relationship図)等で可視化した上で、重複・必須欠損等のデータ品質を確認する。各種研究からは、LLMに投入するデータについて第二正規化(2NF)、一部について第三正規化(3NF)の水準でも十分な成果を享受できるとの示唆が得られている。

2. データの意味付け(セマンティック)── 値の集合を知識に変える
2-1. ステップ1:現場語彙の棚卸しと外部規格との対応
セマンティック処理の出発点は、現場で使用されている専門用語・語彙の棚卸しにある。点検票・作業指示・故障票・報告書から、設備名・部品名・点検項目・作業名・症状・原因を拾い出し、同じ意味の別表記を並べて整理する。たとえば「交換」=「取替え」=「REP」、「ポンプ」=「Pump」といった同義語の対応関係を明確にする作業である。
Woods et al.[4]の研究が80万件の保全作業指示書から7つのコア保全活動用語を特定したように、現場データから体系的に語彙を抽出する手法は学術的にも確立されている。
並行して、外部の標準規格との対応付けを行う。ISO 14224[5](石油・石油化学・天然ガス産業における設備故障・分類体系)やIEC 61360(属性定義)などの用語・分類と、内製の現場用語とのマッピングを整理することで、社内固有の表現と業界標準との間に橋を架ける。
2-2. ステップ2:SKOS規格による辞書化と機械可読化
収集した専門用語を生成AIが理解できる形に変換するための代表的なフレームワークが、W3Cが策定したSKOS(Simple Knowledge Organization System)[6]である。SKOSはConcept(概念)に対して4つの観点から関係性を付与する。
- 代表語(prefLabel): 組織内で統一的に使用する正式名称
- 同義語・略語(altLabel): 現場で併用される別表記
- 上位/下位の関係(broader/narrower): 概念の階層構造
- 関連語(related): 意味的に関連する概念間の参照
加えて、ISO 14224等の標準規格の用語に対してexternalRef(exactMatch/closeMatch)のラベルで紐づけることで、社内辞書と国際規格の間の意味的接続が確保される。


2-3. ステップ3:セマンティックタグの付与
辞書化されたデータを用いて、スキーマで定義した各列(カラム)にセマンティックタグを付与する。タグ付けされたデータとSKOS辞書の両方をLLMに読み込ませることで、「どのデータ項目が何を意味しているか」を生成AIがより正確に理解できるようになる。
タグの体系としては、以下のような分類が用いられる。
- 設備: System / EquipmentType
- 項目: Property / Unit / ComponentType
- 作業: Action / WorkType
- 故障: Symptom / FailureMode
2-4. ステップ4:RDF/OWLによる知識グラフの構築
セマンティック処理の最終段階は、データの関係性をRDF(Resource Description Framework)の概念に則りOWL(Web Ontology Language)形式で記述する知識グラフの構築である。RDFはデータを「主語─述語─目的語」の三つ組(トリプル)として表現するための枠組みであり、OWLはRDFを厳密に記述するための言語として、クラス(Asset等)、プロパティ(partOf等)、制約(domain/range、同値、包含)等の情報をLLMが理解できる形式で表現する。
たとえば設備保全の文脈では、以下のようなトリプルが設備・点検・故障・対策の概念間の関係を機械可読な形で明示する。
- 「冷却ポンプA(Asset)→ hasComponent → ベアリング123(Component)」
- 「点検結果X → indicates → 軸受摩耗(FailureMode)」
- 「軸受摩耗 → mitigatedBy → ベアリング交換(Action)」
このOWL/Turtle形式で記述された知識グラフは、SKOS辞書とともにセマンティックデータとしてLLMにRAG経由で提供され、多段推論の基盤となる。「過去に類似の振動パターンを示した設備で、どのような対策が効果的だったか」という問いに対して、設備→部品→故障モード→対策というグラフ上の経路を辿ることで、根拠のある回答が可能になる。
MIMOSAスタンダード[7]やIndustrial Ontologies Foundry[8]といった産業用オントロジーの標準化も進展しており、保全領域における知識グラフ構築のための参照枠組みは整備されつつある。加えて、OWL記述自体をLLMで支援・生成することも技術的に可能となっており、知識グラフ構築の工数低減にもAIが寄与する局面が広がっている。
3. 構造化+意味付けの統合効果
3-1. 正攻法がもたらす実務的成果
構造化(スキーマ)と意味付け(セマンティック)の統合効果は、具体的には以下のメカニズムを通じて発現する。
スキーマの効果として、正規化されたリレーショナルデータベースでは、LLMが自然言語の問いからSQLクエリを生成する際の安定性が向上する。「設備Aの過去1年間の点検結果を取得せよ」という問いに対して、マスタとトランザクションが適切に分離されていれば、LLMは明確なJOIN条件とWHERE句を含むSQLを生成でき、誤参照や曖昧条件が減少する。データの検索・集約における計算コストも下がり、応答速度の向上にもつながる。
セマンティックの効果として、SKOS辞書とセマンティックタグにより、同義語・表記揺れが吸収される。「ポンプの交換記録を見せて」という質問に対して、「Pump」「取替え」「REP」といった別表記を包含した検索が自動的に行われ、質問者の意図に追従した網羅的な結果が返される。さらにOWLによる知識グラフは、「原因推定→類似事例検索→推奨対策提示」という複数ステップの推論を安定的に実行するための構造的基盤を提供する。
3-2. 正攻法の組み合わせ
第4回で示した通り、非構造化データ(Lv.1)と構造化+意味付けされたデータ(Lv.3)では、複雑質問に対する正答率に20%→83%という4倍以上の差が生じる。この差を生み出しているのは、本記事で詳述した正攻法――古典的な正規化とやや新しい知識グラフ化処理の組み合わせ――である。
構造化は1970年代から確立された正規化の手法であり、セマンティック処理もSKOS・RDF/OWLといった確立された国際標準に基づく。いずれも個々には「枯れた技術」であるが、この組み合わせをLLMの入力データに対して適用することで、生成AIの精度は実用水準に引き上げられる。保全データの処理・管理には正攻法が存在し、その正攻法は特殊な技術ではなく、確立された手法の正しい適用である。
📚 連載:生成AI×設備保全 実践活用ガイド
- 設備保全AI活用の最前線 — 異常検知から知識統合へのパラダイムシフト
- 設備保全AIの導入事例 — グローバル5社の実装状況
- 設備保全AI導入の3ステップ — Zoneモデルとセキュリティ設計
- 設備保全データの品質管理 — AI精度を左右するデータ基盤の実態
- ▶ 設備保全データ構造の実装 — スキーマ設計とセマンティック技術(この記事)
- 設備保全AI活用の実装ロードマップ — シリーズ総括
参考文献
学術論文・技術文書
[1] Codd, E. F., "A Relational Model of Data for Large Shared Data Banks," Communications of the ACM, 1970
https://dl.acm.org/doi/10.1145/362384.362685
[2] Fürst, J., Kosten, C., Nooralahzadeh, F., Zhang, Y., & Stockinger, K., "Evaluating the Data Model Robustness of Text-to-SQL Systems Based on Real User Queries," EDBT 2025
https://arxiv.org/abs/2402.08349
[3] Kimball, R. & Ross, M., "The Data Warehouse Toolkit," 3rd Ed., Wiley, 2013
[4] Woods, C. et al., "An Ontology for Maintenance Activities and Its Application to Data Quality," Semantic Web Journal, 2023
https://www.semantic-web-journal.net/system/files/swj3067.pdf
[5] ISO 14224, "Petroleum, petrochemical and natural gas industries — Collection and exchange of reliability and maintenance data for equipment"
https://www.iso.org/standard/75674.html
標準規格・国際規格
[6] W3C, "SKOS Simple Knowledge Organization System Primer"
https://www.w3.org/TR/skos-primer/
[7] MIMOSA Standards (Machinery Information Management Open Systems Alliance)
[8] Industrial Ontologies Foundry
https://spec.industrialontologies.org/iof/
企業・組織
[9] IBM, "What Is Database Normalization?"
https://www.ibm.com/jp-ja/think/topics/database-normalization
次回予告
第6回: EMLink Intelligenceにみるデータ構造の実装
- スキーマ+セマンティックを組み込んだ設備管理プラットフォームの実際
- Zone2を実現するためのアーキテクチャ設計