【生成AI×設備保全 #4】設備保全データの品質管理 — AI精度を左右するデータ基盤の実態
設備保全データをそのままChatGPTに投入しても精度は出ない。非構造化データと構造化+意味付けデータでは回答精度に4倍以上の差が生じる。AI精度を左右するデータの構造化(スキーマ)と意味付け(セマンティック)の二本柱を分析する。

1. 非構造化データとLLM精度 ── 生データ投入の限界
1-1. 現場で起きている期待と現実のギャップ
Zone2への移行を試みる企業がまず直面するのは、「AIに自社データを投入したが、期待したほど正確な回答が得られない」という事態である。設備台帳(固定資産台帳)、保全履歴・故障履歴、保全計画、点検帳票フォーマット――これらは多くの現場でExcelやPDF、あるいは紙の帳票として存在する。これらの「そのままの状態」のデータをLLMに渡しても、回答の正確性と安定性には顕著な限界が生じる。
具体的な症状として現場担当者が報告するのは、以下のような事象である。
- 「答えが日によって変わる」(回答の再現性がない)
- 「いくらプロンプトを工夫しても今一つ的確でない」(質問意図の把握が不安定)
- 「単純な質問には答えるが、複雑な問いにはほとんど答えてくれない」(推論の深さに限界)
これらは生成AIモデル自体の能力不足というよりも、投入されるデータの構造に起因する問題であることが、近年の研究で明確になってきている。

1-2. 「AIモデルの問題」ではなく「データの問題」である
Müller et al.がICIS 2025で報告した研究[1]は、RAG(検索拡張生成)システムにおけるデータ品質課題を体系的に整理した。同研究は品質問題を4つの処理段階(データ抽出・データ変換・プロンプト/検索・生成)にわたる15のデータ品質次元として分類し、問題がパイプラインの上流――すなわちデータの抽出と変換の段階――に集中していることを明らかにしている。
この知見が示唆するのは、生成AIの出力精度を改善するには、AIモデルの側を高性能なものに入れ替えるよりも、入力データの品質を上流で担保するほうが効果的だという点である。GPT-4をGPT-5に替えることよりも、投入するデータの構造を整えることのほうが、回答精度への寄与度が高い。
Biswal et al.がCIDR 2025で発表した論文[2]も同様の結論を支持している。同研究はText2SQL(自然言語からSQL文を生成する技術)単体ではユーザーが実際に問いたい質問の大半に対応できないことを示し、データベースの構造設計とAIの推論能力を統合するTAG(Table-Augmented Generation)の枠組みを提唱している。
1-3. データ品質とLLM精度の定量的関係
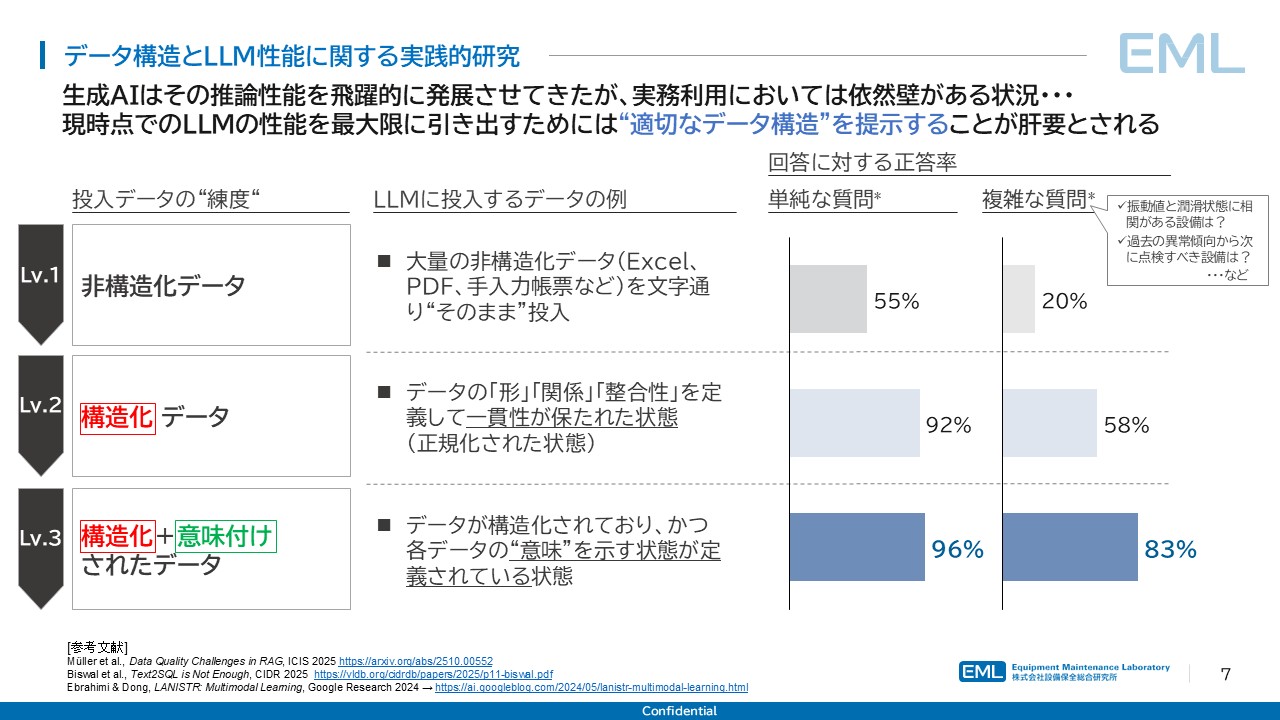
投入データの「練度」を3段階に分けると、LLM回答精度との関係はより具体的に見えてくる。
投入データの状態 | 定義 | 単純な質問に対する正答率 | 複雑な質問に対する正答率 |
|---|---|---|---|
--- | --- | --- | --- |
Lv.1 非構造化データ | Excel・PDF・手入力帳票をそのまま投入 | 55% | 20% |
Lv.2 構造化データ | データの形・関係・整合性を定義し、一貫性が保たれた状態 | 92% | 58% |
Lv.3 構造化+意味付けされたデータ | 構造化されており、かつ各データの意味を示す定義がなされている状態 | 96% | 83% |
Lv.1(非構造化)からLv.2(構造化)への改善幅は、単純質問で37ポイント、複雑質問で38ポイントに達する。さらにLv.2からLv.3(構造化+意味付け)への追加改善も、複雑質問で25ポイントという大きな差を生んでいる。
とりわけ注目すべきは複雑質問における変化である。「振動値と潤滑状態に相関がある設備はどれか」「過去の異常傾向から次に点検すべき設備はどれか」といった、現場が真に必要とする質問への正答率が、非構造化データの20%から構造化+意味付けにより83%まで引き上げられる。この差は、保全現場においてAIが実用に耐えるか否かを左右する水準差である。
非構造化データ(Lv.1)と適切に処理されたデータ(Lv.3)で回答精度に4倍以上の差が生じるという事実は、「保全AI活用の9割はデータ構造で決まる」と弊社が考える所以でもある。
2. AI精度を支える二本柱:スキーマとセマンティック
2-1. 構造化(スキーマ)とは何か
生成AIの出力精度を実用水準に引き上げるために必要なデータ処理の第一の柱は、データの構造化(スキーマ / Schema)である。これは、データの形・関係・整合性を設計し、一貫性や各データの依存関係を正しく保証する操作を指す。
E. F. Coddが1970年に提唱した関係モデル[3]を理論的基盤とし、具体的にはデータモデリング(データ間の関係性を描く)、データ正規化(正しく分離して形を整える)、キー整備(識別と結合の結び目を設計する)といった手法から構成される。
LLMにとっての効用は明確である。データの構造が正規化されていれば、Text2SQL(自然言語からSQLクエリを生成する技術)が安定的に生成され、誤参照や曖昧な条件指定が減少する。Fürst et al.がEDBT 2025で報告した研究[4]は、データモデルの設計がText2SQLシステムの正答率に顕著な影響を与えることを、実ユーザー質問6,000件をもとに実証している。スキーマの設計次第でSQL生成の正答率に20〜41%の幅が生じるという結果は、データの形を整えることの重要性を裏付ける。
2-2. 意味付け(セマンティック)とは何か
第二の柱は、データの意味付け(セマンティック / Semantic)である。これは、データに内包される語彙・分類・関連性を定義し、単なる値の集合を「知識」に変える操作を指す。
Woods et al.がSemantic Web Journal 2023で報告した研究[5]は、80万件の保全作業指示書からNLP(自然言語処理)を用いて7つのコア保全活動用語とその同義語を特定し、ISO 14224[6]およびISO 15926-4との整合性を確保した体系を提示している。このように、保全現場の語彙を体系的に整理し、各データに「意味」を与える処理がセマンティックの核心である。
LLMにとっての効用は、同義語・表記揺れの吸収(「交換」=「取替え」=「REP」、「ポンプ」=「Pump」)による質問意図への追従、ハルシネーション(AIが事実に基づかない回答を生成する現象)の段階的低減、そして原因推定・類似事例検索・推奨対策提示といった複雑な多段推論への回答安定化である。
2-3. 両者は代替関係ではなく補完関係にある
ここで強調すべきは、スキーマとセマンティックは「どちらか一方で十分」という代替関係ではなく、「双方が揃ってはじめて実効性を発揮する」補完関係にあるという点である。
Biswal et al.[2]が提示したTAG(Table-Augmented Generation)の枠組みは、この補完性を理論的に裏付ける。従来のText2SQL手法はリレーショナル代数で表現可能な質問のみを対象とし、RAGはデータベース内の少数レコードへの参照で回答可能な質問のみを扱う。しかし現実のユーザーが問いたい質問の大半は、ドメイン知識・一般知識・正確な計算・意味的推論の組み合わせを要求するものであり、データベースシステムの論理的推論能力とLLMの自然言語推論能力の統合が必要となる。
Ebrahimi & Dongが2024年にGoogle Researchで発表したLANISTR[7]もまた、構造化データ(表形式・時系列)と非構造化データ(テキスト・画像)を横断的に学習するマルチモーダルフレームワークとして、構造と意味の統合が精度向上に直結することをAUROC(分類精度の指標)6.47%改善という数値で示している。
つまり、構造化(スキーマ)は「正しく検索できる土台」を、意味付け(セマンティック)は「正しく理解できる文脈」を提供し、この両輪が揃うことで生成AIは実用的な回答精度を獲得する。先のLv.2(構造化のみ)とLv.3(構造化+意味付け)の比較において、複雑質問の正答率が58%から83%へと25ポイント改善したのは、まさにこの補完効果の表れである。

3. 「保全AI活用の9割はデータ構造で決まる」
以上の分析が示すのは、生成AIの精度を決定する変数の中で、モデル選択やプロンプト設計以上にデータの構造と意味の整備が大きな影響力を持つという点である。
非構造化データでは最先端のLLMを用いても複雑質問への正答率は20%にとどまる一方、適切に構造化+意味付けされたデータではモデルの性能を最大限に引き出すことが可能となる。この構造は、設備保全に限った話ではなく、生成AIを業務に活用しようとするあらゆる領域に共通する基本原則である。
そして重要なのは、保全データの処理・管理には正攻法が存在するという点である。構造化は1970年代から確立された正規化の手法であり、セマンティック処理もW3CのSKOS[8]やRDF/OWLといった国際標準に基づくものである。いずれも「枯れた技術」の組み合わせであるが、LLM時代にこそ、その価値が再発見されている。
次回(第5回)では、この正攻法の具体的な実装手順――スキーマの設計ステップとセマンティックの付与方法――を、保全データの実例とともに詳述する。
📚 連載:生成AI×設備保全 実践活用ガイド
- 設備保全AI活用の最前線 — 異常検知から知識統合へのパラダイムシフト
- 設備保全AIの導入事例 — グローバル5社の実装状況
- 設備保全AI導入の3ステップ — Zoneモデルとセキュリティ設計
- ▶ 設備保全データの品質管理 — AI精度を左右するデータ基盤の実態(この記事)
- 設備保全データ構造の実装 — スキーマ設計とセマンティック技術
- 設備保全AI活用の実装ロードマップ — シリーズ総括
参考文献
学術論文・技術文書
[1] Müller, L., Holstein, J., Bause, S., Satzger, G., & Kühl, N., "Data Quality Challenges in Retrieval-Augmented Generation," ICIS 2025
https://arxiv.org/abs/2510.00552
[2] Biswal, A., Patel, L., et al., "Text2SQL is Not Enough: Unifying AI and Databases with TAG," CIDR 2025
https://arxiv.org/abs/2408.14717
[3] Codd, E. F., "A Relational Model of Data for Large Shared Data Banks," Communications of the ACM, 1970
https://dl.acm.org/doi/10.1145/362384.362685
[4] Fürst, J., Kosten, C., Nooralahzadeh, F., Zhang, Y., & Stockinger, K., "Evaluating the Data Model Robustness of Text-to-SQL Systems Based on Real User Queries," EDBT 2025
https://arxiv.org/abs/2402.08349
[5] Woods, C. et al., "An Ontology for Maintenance Activities and Its Application to Data Quality," Semantic Web Journal, 2023
https://www.semantic-web-journal.net/system/files/swj3067.pdf
[6] ISO 14224, "Petroleum, petrochemical and natural gas industries — Collection and exchange of reliability and maintenance data for equipment"
https://www.iso.org/standard/75674.html
[7] Ebrahimi, S., Arik, S., Dong, Y., & Pfister, T., "LANISTR: Multimodal Learning from Structured and Unstructured Data," Google Research, 2024
https://arxiv.org/abs/2305.16556
標準規格
[8] W3C, "SKOS Simple Knowledge Organization System Primer"
https://www.w3.org/TR/skos-primer/
次回予告
第5回: 保全データの正攻法 ── スキーマとセマンティックの実装
- 構造化(スキーマ)の具体的ステップ:棚卸し → デジタル化 → クリーニング → マスタ整備 → リレーション構築
- 意味付け(セマンティック)の具体的ステップ:語彙棚卸し → SKOS辞書化 → セマンティックタグ付与 → RDF/OWL知識グラフ構築
- 構造化+意味付けの統合効果